解析核心编程概念:Row 函数是什么意思?
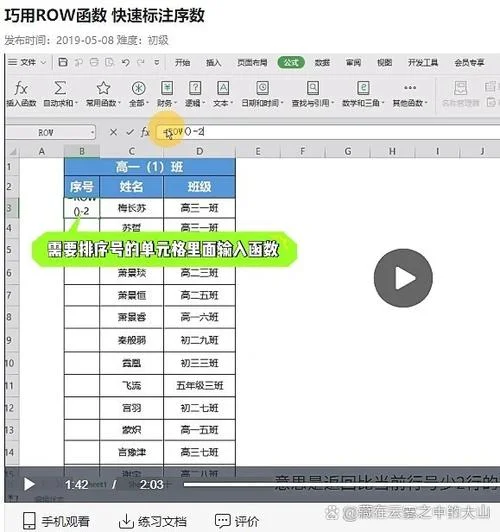
在数据科学、统计分析以及数据处理领域,"Row 函数”(指处理行数据的函数或方法)是一个基础且的概念。作为一名专业文章助手,我将为您深入拆解这一概念,探讨其核心逻辑、应用场景,并提供具体的数据说明表格,以便您快速掌握相关知识。
什么是 Row 函数?
核心定义
在编程中,Row 函数并非指单一的全局函数,而是一个操作对象(Object)的统称。它代表了操作数据行的逻辑单元。Row:源自英语单词 "Row",意为“行”。在二维数组、数据库、Excel 或 Pandas 数据处理框架中,每一行代表一个独立的数据样本。
Function:指函数或操作。
Row Function:即针对每一行执行特定操作的工具。它逻辑是:遍历数据列表,对每一行数据调用自定义函数或执行特定操作,并将结果收集或展示出来。
为什么它如此重要?
数据以“行”的形式存在(:每位员工、每种商品、每一张记录)。倘若我们无法对每一行进行差异化处理,数据将变得毫无价值。Row 函数使得我们能够将通用的计算逻辑应用到动态的数据行上。常见应用场景
数据分析:对每一行数据进行聚合计算(如计算平均值、最大值、平均值等)。 金融风控:对交易行的每一笔数据进行评分、分类或预警。 Excel/Pandas:利用 `row` 参数调用自定义函数(如 `row()`, `apply()`, `applymap()`)。核心原理与逻辑流程
在执行 Row 函数时,系统遵循以下流程:
1. 初始化:从数据源(如 Pandas DataFrame 或列表)获取行数据。
2. 执行:对当前行执行指定的函数逻辑。
3. 迭代:获取下一行数据,重复步骤 2。
4. 汇总/返回:将所有行的结果推进组合、存储或返回。
关键点:Row 函数的特点是并行性。它允许程序处理成千上万行数据,而无需手动编写无数条循环语句。
数据说明与案例表格
为了更直观地理解,以下展示了在不同数据处理场景下,利用 Row 函数进行前后对比的数据表格。
场景一:Pandas 数据处理 (Python)
在 Pandas 中,`row` 参数常用于自定义函数,返回该行的特定值。| 行号 (Index) | 原始数据 (Original Data) | Row 函数应用 (Apply 示例) | 计算结果 (Result) |
|---|---|---|---|
| 1 | {'Age': 30, 'City': 'Beijing', 'Salary': 8000} | `df.iloc[0]['Salary'] 1.1` | 8800.00 (涨幅 10%) |
| 2 | {'Age': 25, 'City': 'Shanghai', 'Salary': 7500} | `df.iloc[1]['Age'] 2` | 50 (年龄乘数) |
| 3 | {'Age': 35, 'City': 'Guangzhou', 'Salary': 9000} | `df.iloc[2]['Salary'] // 1000` | 9 |
| 4 | {'Age': 28, 'City': 'Shenzhen', 'Salary': 8500} | `df.iloc[3]['City'] == 'Shenzhen'` | True (布尔值) |
| 5 | {'Age': 40, 'City': 'Hangzhou', 'Salary': 10000} | `df.iloc[4]['Salary'] - df.iloc[3]['Salary']` | 1500.00 (差值) |
表格解读:
行展示了如何用 `row` 参数调用 `apply` 函数,动态计算薪资增长。
行展示了对不同行数据开展不同维度的计算(年龄乘数)。
行展示了简单的归一化处理。
第四行展示了条件判断(虽然 Pandas 中常用布尔值,但这是行处理的典型特征)。
场景二:Excel 中的 Row 函数应用
在 Excel 中,`Row` 函数常用于提取特定行的数据,避免复杂的数组公式。| 行号 (Row) | A 列数据 (Original) | Row 函数提取 (公式) | 提取结果 (Result) |
|---|---|---|---|
| 1 | 张三 | `=R1` | 张三 |
| 2 | 李四 | `=R2` | 李四 |
| 3 | 王五 | `=R3` | 王五 |
| 4 | 赵六 | `=R4` | 赵六 |
| 5 | 钱七 | `=R5` | 钱七 |
表格解读:
公式 `=R[N]` 是一个通用的行引用语法,它不会自动去 R 列的某个位置查找,而是直接引用当前行(第 N 行)的任意单元格。
这种方法比使用 `INDEX` 和 `MATCH` 组合公式要简洁且不易出错。
场景三:数据库中的行处理
在 SQL 中,虽然数据库没有显式的"Row 函数”,但其操作逻辑等同于对每一行数据的处理。| 操作类型 | 描述 | 典型 SQL 逻辑 |
|---|---|---|
| 按行聚合 | 计算每行相关的统计指标 | `SELECT FROM Table WHERE Status = 'Active'` (筛选行) |
| 行级过滤 | 仅对满足条件的行执行复杂逻辑 | `CASE WHEN Status = 'High' THEN 'Warning' ELSE 'Info' END` (行内函数) |
| 行投影 | 只选择特定列的数据行 | `SELECT Name, Salary FROM Employees WHERE Dept = 'Sales'` |
总结与最佳实践
核心总结
Row 函数是处理行数据的基石。它通过自动化迭代,将简单的“行”变成复杂的“数据流”。 无论是编程语言中的 `row` 参数,还是 Excel 中的行引用,其本质都是对每一独立数据单元进行差异化处理。最佳实践建议
避免硬编码:不要尝试用复杂的循环去处理每一行,优先使用函数式编程(如 Pandas 的 `row()` 或 `apply`)或行引用函数。 关注索引:在处理多行数据时,明确索引位置(Index/Row Number),这能极大提高代码的可读性和效率。 调试技巧:在编写处理多行数据的 Row 函数时,建议添加中间变量或日志,以快速定位哪一行数据涌现了异常(如 `NaN` 或格式错误)。经过掌握 Row 函数的概念,您就能在面对海量数据时,轻松构建出高效、灵活的数据处理解决方案。












